ASIC芯片专题:揭秘博通大涨之谜系列(一)
事件:AI芯片行业变天,博通市值突破1万亿美金。12月17日消息,美股AI网络芯片公司博通(Broadcom,NASDAQ: AVGO)近期发布财报后股价飙升,连续两个交易日累计涨38%,收于250美元/股,公司市值已突破万亿美元大关(最新市值为1.17万亿美元),成为全球第九家市值超过1万亿美元的公司,同时也是全球第三家市值超越1万亿的半导体公司。博通CEO陈福阳日前表示,该公司正与3个大客户一起开发ASIC(专用集成电路)AI芯片。他估算,到2027年,市场对定制款AI芯片ASIC(专用集成电路)的需求规模将达600亿-900亿美元。
经过多年的迭代升级,2024年谷歌发布了第六代TPU芯片Trillium,计算性能较上代产品提升4.7倍,内存带宽提升1倍,能耗优化67%。谷歌并未对外销售TPU芯片,但TechInsights预计2023年谷歌自用的TPU芯片已经达到200万颗,仅次于英伟达的市场规模。在AI ASCI芯片领域,英特尔也成为重要的参与者。
在AI ASIC需求快速增长的背景下,以博通、Marvell为代表的公司迎来了业绩爆发期。根据博通发布的财报数据,公司2024财年AI收入大增2.2倍至122亿美元。博通正与三个大型客户开发AI芯片,预计2025年AI芯片业务收入达到150亿-200亿美元。 随着AI技术的发展及端侧AI需求的快速增长,ASIC将在AI推理、AI消费电子产品方面扮演着重要的角色。
一、AI芯知多少
作为一种AI芯片,TPU是专用集成电路(ASIC)的代表。主流AI芯片架构包括GPGPU、ASIC和FPGA,一般认为GPGPU为改善CPU效率而生,而TPU可以进一步改善GPGPU未优化完全的部分,三者是从通用到专用不断演进的过程。
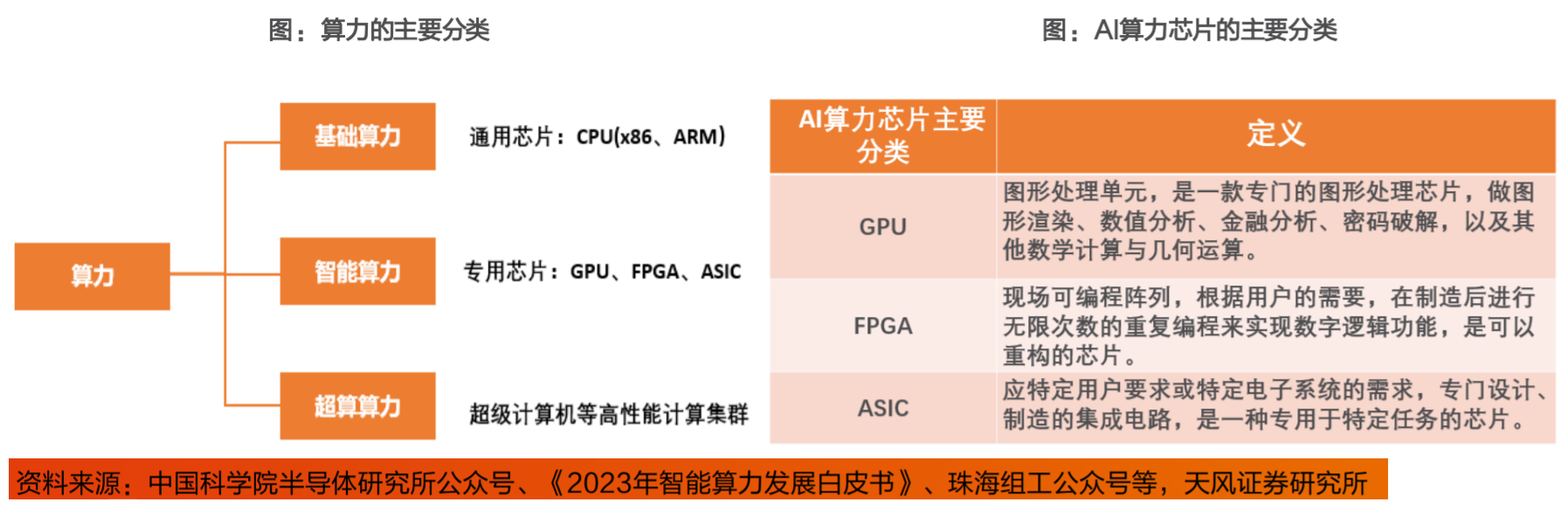
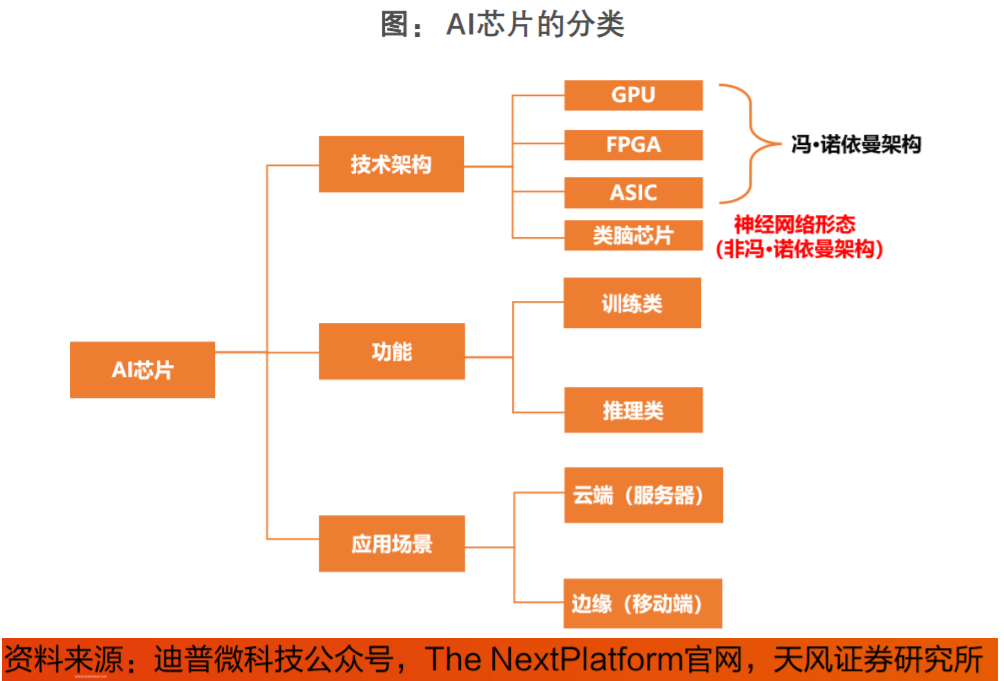
目前AI芯片通常采用GPU与ASIC架构。目前通用的CPU、GPU、FPGA等都能执行Al算法,只是执行效率差异较大。但狭义上讲一般将Al芯片定义为“专门针对A算法做了特殊加速设计的芯片”。Al芯片可以分为GPU、FPGA和ASIC架构,根据场景可以分为云端和端侧。
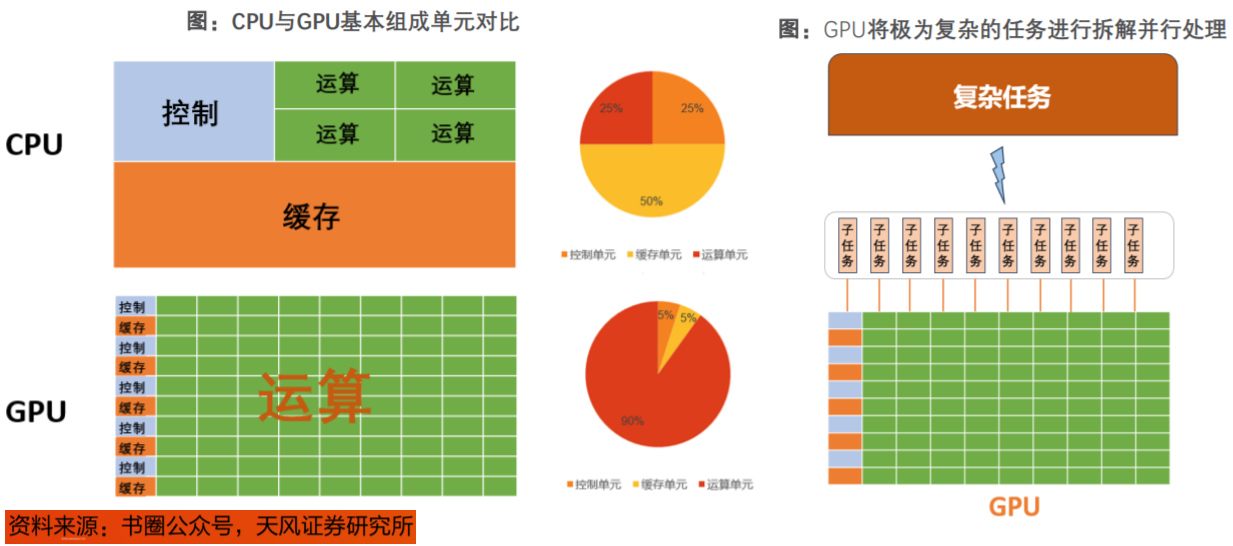
CPU和GPU在架构组成上都包括3个部分:运算单元(ALU)、控制单元(Control)、缓存单元(Cache)。从结构上看,在CPU中,缓存单元占50%,控制单元占25%,运算单元占25%;而在GPU中,运算单元占90%比重,缓存、控制各占5%;由此可见,CPU运算能力更加均衡,GPU更适合做大量运算。
GPU通过将复杂的数学任务拆解成简单的小任务,并利用其多流处理器来并行处理,从而高效地执行图形渲染、数值分析和AI推理。
通常GPU核心可分为三种:CUDACore、TensorCore、RTCore。每个CUDA核心含有一个ALU(整数单元)和一个浮点单元,并且提供了对于单精度和双精度浮点数的FMA指令。
如果将GPU处理器比作玩具工厂,CUDA核心就是其中的流水线。流水线越多,生产的玩具就越多,虽然“玩具工厂”的性能可能会越好,但也受限于每个流水线的生产效率、生产设备的架构、生产存储资源能力等。反应在GPU上,还需考虑显卡架构、时钟速度、内存带宽、内存速度、VRAM等因素。

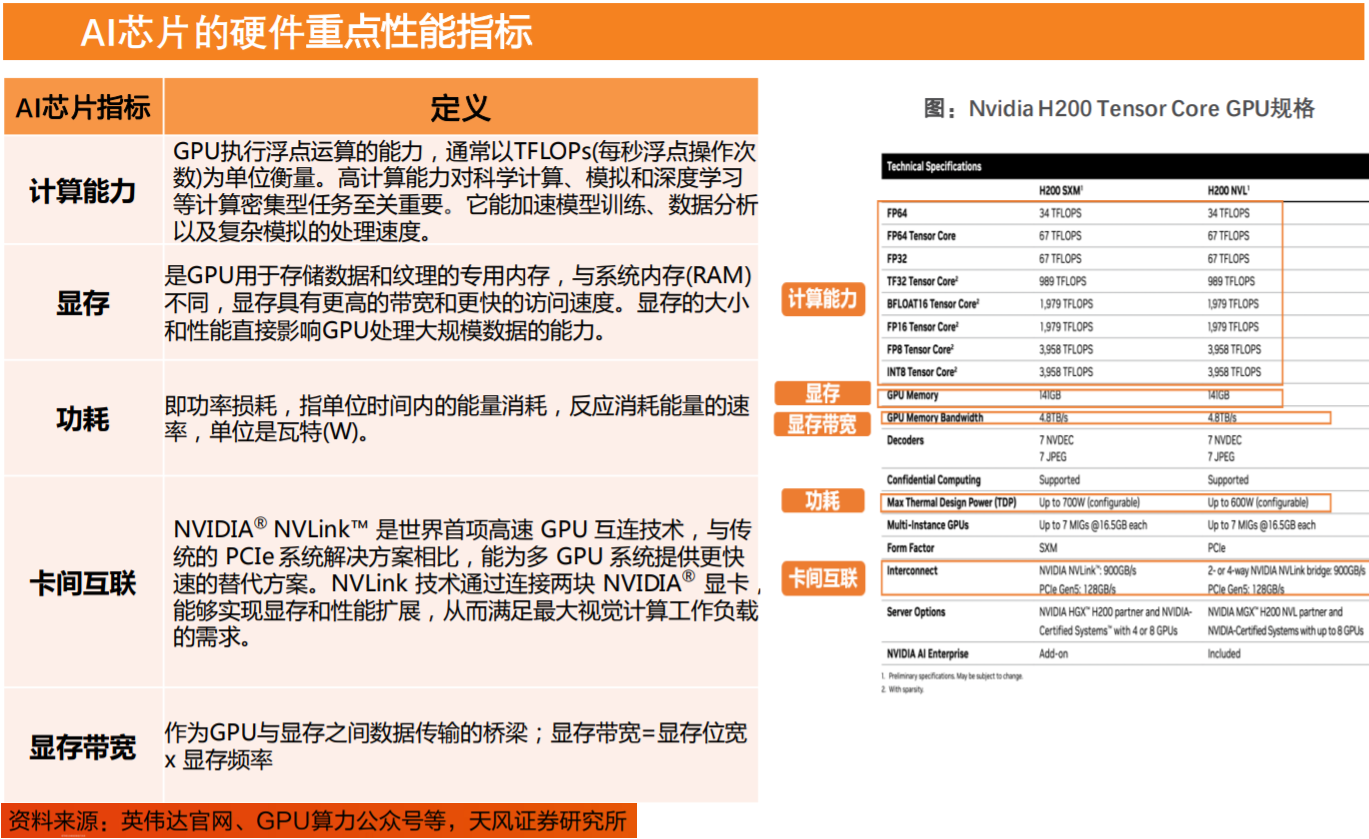
和其他芯片相比,AI芯片重点增强了运行AI算法的能力。目前主流AI芯片为GPU和ASIC。国际上,Nvidia的H200TensorCoreGPU以其卓越的计算性能和能效比领先市场,而Google的第六代TPUTrilliumASIC芯片则以其专为机器学习优化的设计提供高速数据处理。在国内,寒武纪的思元370芯片(ASIC)凭借其先进的计算处理能力在智能计算领域占据重要地位,已与主流互联网厂商开展深入适配;海光信息的DCU系列基于GPGPU架构,以其类“CUDA”通用并行计算架构较好地适配、适应国际主流商业计算软件和Al软件。
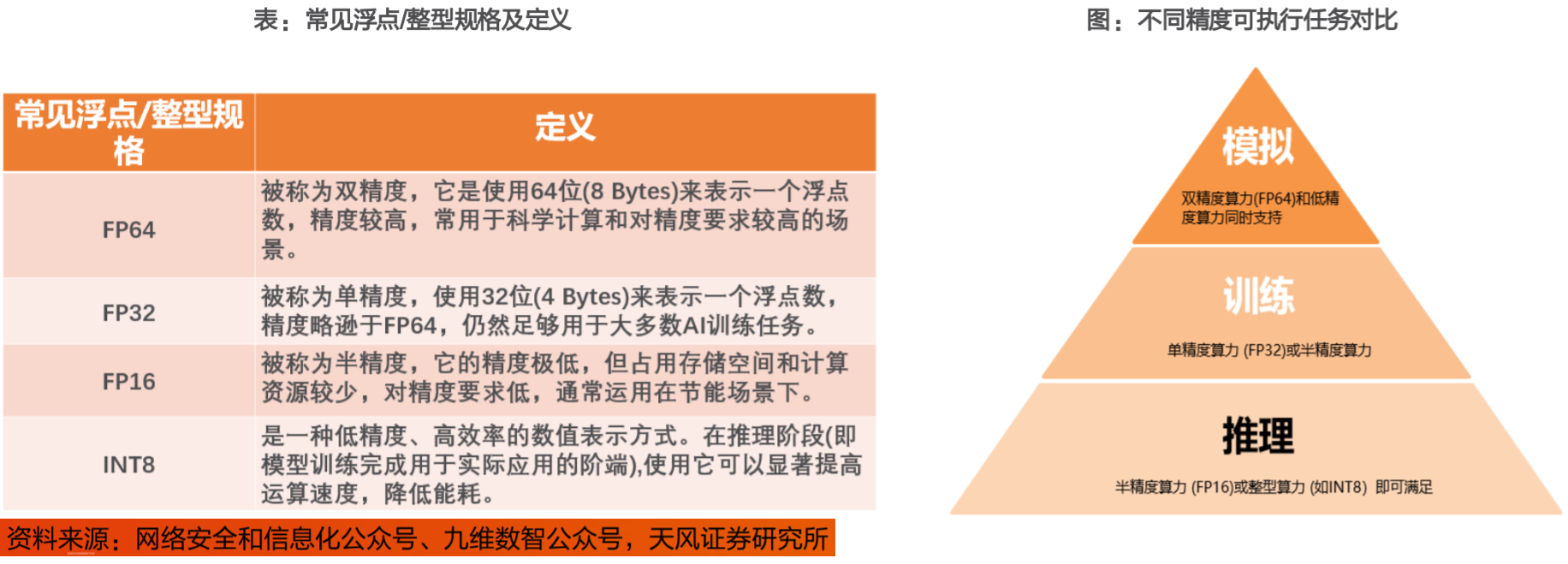
算力的通常计量单位:

不同场景对应算力精度表示不同:
稀疏算力和稠密算力:

AI芯片的硬件重点性能指标:计算能力(浮点运算能力)、显存、功耗、卡间互联、显存带宽。
ASIC-AI芯片:TPU布局及性能对比。与传统CPU、GPU架构不同,TPU的MXU设计采用了脉动阵列(systolicarray)架构,数据流动呈现出周期性的脉冲模式,类似于心脏跳动的供血方式。
CPU与GPU在每次运算中需要从多个寄存器中进行存取;而TPU的脉动阵列将多个运算逻辑单元(ALU)串联在一起,复用从一个寄存器中读取的结果。
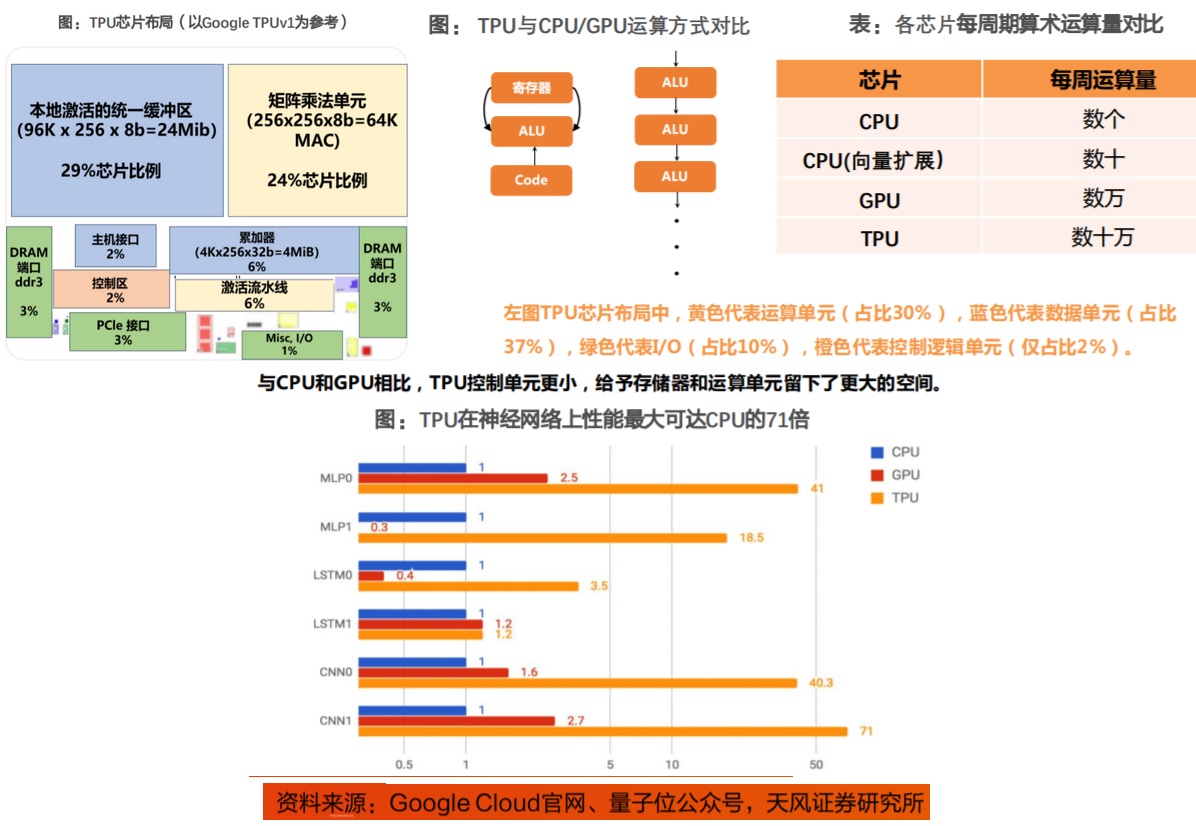
TPU在性能功耗比、集群算力利用率上相较于GPGPU有较大优势。主要由于:
(1)芯片层面:TPU专为矩阵乘法而设计,脉动阵列、低精度等设定均适用于AI算法,能够处理大量数据以及复杂的神经网络;
(2)集群层面:谷歌自研光学芯片Palomar,构建集群互连优势;TPU与TensorFlow良好适配,软件与硬件相得益彰,能够发挥出11>2的效果。站在当下回望,我们发现,TPU具备的优势其实最终都形成了AI芯片共同的趋势,在优化方向上大同小异,而谷歌的强大在于“前瞻”。
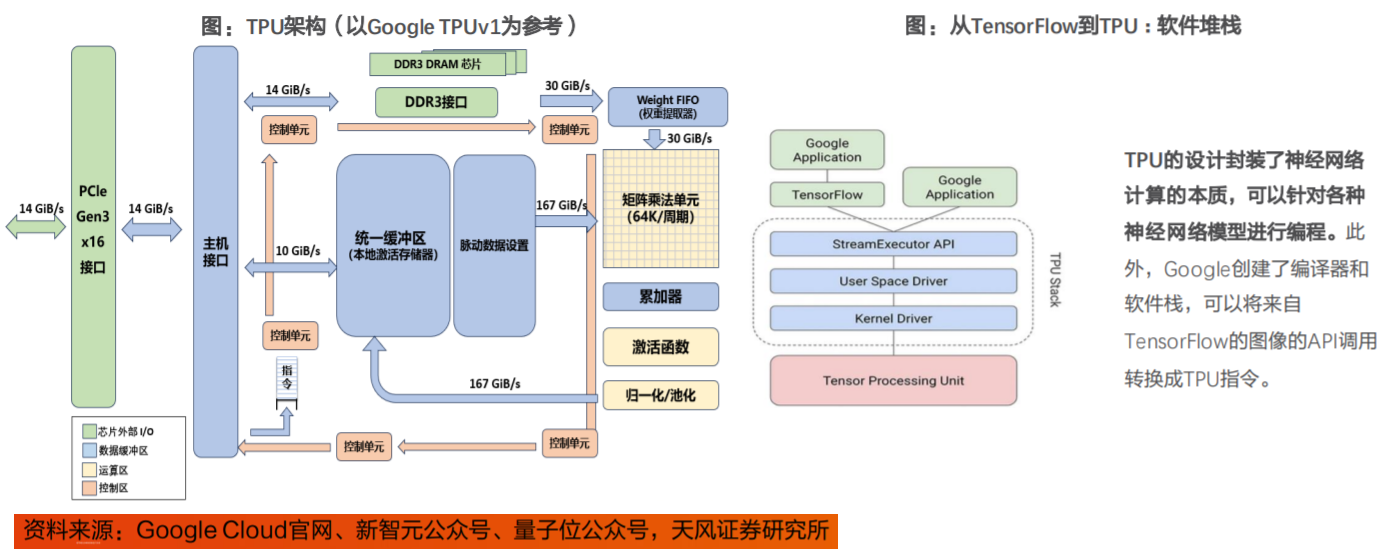
TPU(张量处理单元)属于ASIC的一种,是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,为机器学习领域而定制。
TPUv1依赖于通过PCle(高速串行总线)接口与主机进行通信;它还可以直接访问自己的DDR3存储。
矩阵乘法单元:256x256大小的矩阵乘法单元,顶部输入256个权重值,左侧是256个input值。
DDR3DRAM/WeightFIFO:权重存储通过DDR3-2133接口连接到TPUv1的DDR3RAM芯片中,权重通过PCle从主机的内存预加载,然后传输到权重FIFO存储器中,供矩阵乘法单元使用。
统一缓存区/脉动数据设置:应用激活函数的结果存储在统一缓冲区存储器中,然后作为输入反馈矩阵乘法单元,以计算下一层所需的值。
TPU的运算资源包括:
•矩阵乘法单元(MXU):65536个8位乘法和加法单元,运行矩阵计算。
•统一缓冲(UB):作为寄存器工作的24MB容量SRAM。
•激活单元(AU):硬件连接的激活函数。
参考资料:
20241023-华福证券-TPU:为更专用的AI计算而生
20240807-天风证券-算力知识普惠系列一:AI芯片的基础关键参数
投资顾问:王德慧(登记编号:A0740621120003),本报告中的信息或意见不构成交易品种的买卖指令或买卖出价,投资者应自主进行投资决策,据此做出的任何投资决策与本公司或作者无关,自行承担风险,本公司和作者不因此承担任何法律责任。
免责声明:以上内容仅供参考学习使用,不作为投资建议,此操作风险自担。投资有风险、入市需谨慎。
推荐阅读
相关股票
相关板块
相关资讯

扫码下载
九方智投app

扫码关注
九方智投公众号
头条热搜
涨幅排行榜
上海九方云智能科技有限公司 版权所有
证券投资咨询机构业务机构许可证:ZX0023
办公地址:上海市青浦区徐民东路88号1F(北塔、西北裙、东北裙、南裙)、2F(西北裙、南塔)、3F(北、西北裙、东北裙、南塔)、5F(南、北)、6F(南、北)、7F(南、北)、8F(南、北)、9F(南、北)、10F(南、北)、11F北、12F(南、北)
注册地址:上海市普陀区云岭东路89号12层1202室
 沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058 转3
沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058 转3
总经理信箱:xht_sh@newwinner.com.cn
















暂无评论
赶快抢个沙发吧