【行业洞察】华为韬定律弯道超车:从“空间”转向“时间”要性能
华为"韬定律"弯道超车:从“空间”转向“时间”要性能
一、在全球卡脖子、制程逼近物理墙的当下,韬定律不是简单“替代摩尔”,而是开辟第二条、更可持续的高速赛道——是后摩尔时代的一记绝杀。
5月25日,上海举办的2026国际电路与系统研讨会(IEEE ISCAS)迎来重磅突破。华为公司董事、半导体业务部总裁何庭波在《半导体新路径探索与实践》主旨演讲中,正式发布“韬(τ)定律”—— 这是中国在全球半导体领域首次提出的产业发展指导新原则,为陷入瓶颈的全球芯片产业指明全新演进方向。
后摩尔时代困境:传统路径走到尽头。过去五十余年,摩尔定律凭借“几何缩微”(持续缩小晶体管尺寸)的核心逻辑,推动半导体产业飞速发展,晶体管密度与性能不断提升、成本持续下降。但如今,这一经典定律正遭遇物理极限与经济效益的双重瓶颈。
随着制程逼近原子级,晶体管缩小难度陡增、工艺成本指数级飙升,“几何缩微”的红利逐渐消退。与此同时,人工智能、高性能计算等领域对算力的需求呈指数级增长,传统工艺已难以匹配产业需求。探索一条不依赖物理尺寸缩小、可持续演进的新路径,成为全球半导体行业的共同使命。
韬定律:以“时间缩微”重构半导体演进逻辑。在此背景下,华为提出的“韬定律”跳出传统框架,核心是用“时间缩微”替代“几何缩微”,将产业发展的核心从“缩小空间尺寸”转向“压缩时间损耗”。
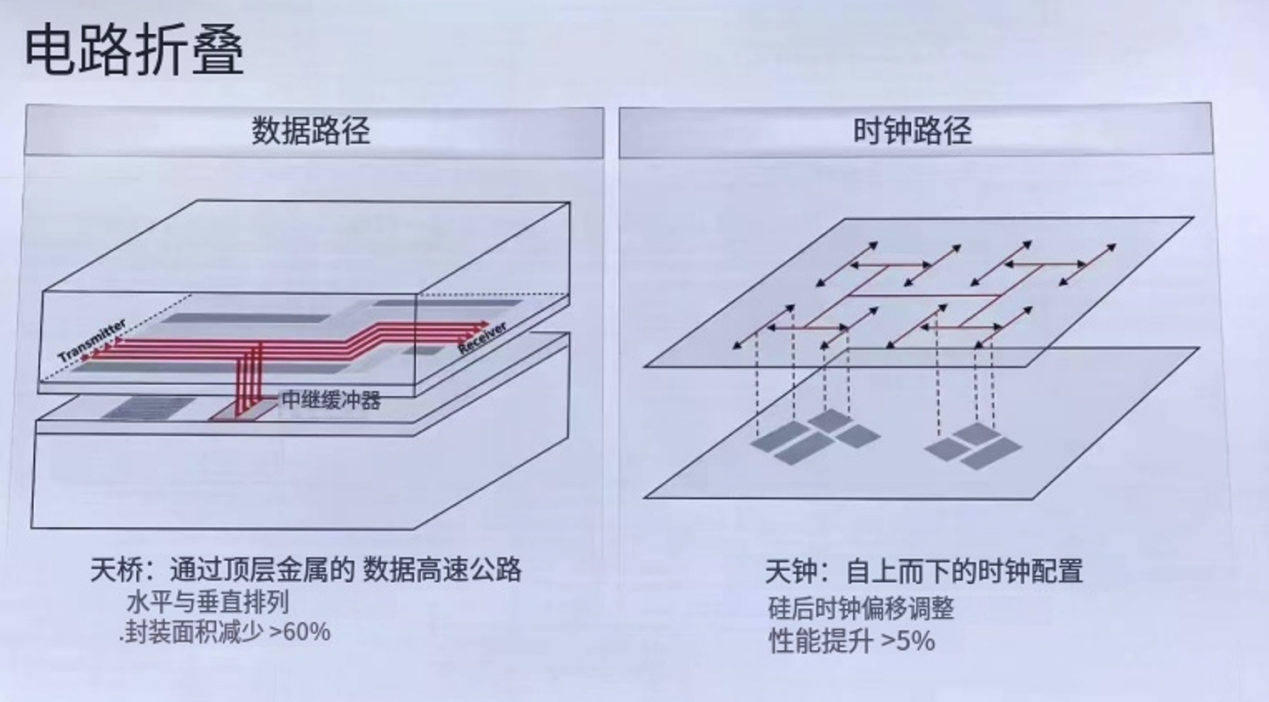
摩尔定律:把管子做更小→空间换性能;更小、更快、更贵(难以为继);
韬定律:把信号跑更快→时间换性能,更快、更密、更可控(无限演进)。

绕开物理极限:不再死磕3nm/2nm/1nm,避开量子效应、漏电、成本陷阱;
自主可控+破封锁:在外部制程限制下,靠架构/电路/系统创新实现性能超车;
全栈体系化:从器件→电路→芯片→系统→软件多层级协同优化,不是单点技术,是完整新范式华为;
技术层级 | 核心优化目标 | 关键技术手段 | 优化逻辑 |
器件层 | 缩微器件级固有时间常数 | 优化晶体管结构、调整互连材料、降低寄生电阻与寄生电容 | 从物理底层入手,减少晶体管本身的开关时延,以及电流在互连线路上的传输损耗,从根源上压缩τ的基础值 |
电路层 | 缩短关键信号传输路径 | 逻辑折叠(LogicFolding)技术、自由逻辑设计架构 | 打破传统平面电路布局的限制,将平面电路重构为多层立体结构,让信号不再走平行“长路”,而是走垂直“近道”,直接缩短信号传输的物理距离 |
芯片层 | 减少芯片内计算单元的通信损耗 | 立体堆叠集成、自研片内互联总线、时钟树优化 | 在单颗裸片内部,将不同功能的计算单元垂直堆叠,优化数据传输接口,减少不同单元间的信号传输时延 |
系统层 | 降低多芯片/多节点互联时延 | 灵衢自研高速互联总线、MatrixLink全光互联、UBSwitch芯片 | 从系统级架构入手,缩短芯片间、机柜间的信号传输路径,将多颗芯片的协同通信时延压缩至百纳秒级,构建低延迟、高带宽的全链路互联体系 |
1.器件层面:通过优化晶体管和互连电阻及寄生电容,从物理底层最大限度缩微器件级时间常数τ。
传统晶圆层面工艺优化,如台积电GAA,全环绕栅极提升沟道控制力,背电工艺,降低漏电流与寄生电容。国内底层差距最大的部分,要靠后面的来弯道超车。
2.电路层面,通过逻辑折叠技术突破传统平面布局的物理边界,显著缩短关键路径的走线长度并有效降低信号传播的电阻和电容负载,实现晶体管密度和电路性能大幅提升。靠堆叠和先进封装,弥补芯片层级工艺的差距。华为逻辑折叠技术,将平面电路立体堆叠,关键路径缩短40%,密度提升2倍。
英伟达A100/H100开始,到GB再到VR以来沿用的cowos封装;
AMD最擅长,MI300X开始采用的Chiplet+3DV-Cache,折叠关键逻辑块,减少长距离布线,延迟降低25%;
长存最引以为傲的3Dstaking,让NAND工艺实现弯道超车;
3.芯片层面:通过“软件、架构、芯片”的全栈软硬芯协同设计,基于实际工作负载实现指令流和数据流的细粒度控制,提高系统级并行度和效率,大幅降低端到端执行时间。单卡的整体性能优化,在芯片和封装这些物理优化基础上,进一步软件优化。以及内存、闪存、网络,在单卡局域范围内的整体优化:
英伟达GH200开始,用ARMCPU扩大内存调用,集成GraceCPU与HopperGPU,CUDA+NVLink-C2C协同,统一内存细粒度调度;
华为昇腾910B依托达芬奇架构与CANN软件栈,软硬件协同优化算子与数据流;
寒武纪思元370搭载MLUarch03与MagicMind软件,训推一体协同,动态调度指令与数据;
单卡NVlink走向柜外,成为更大范围内的“互联神经网络”。
4. 超节点,系统层面:定义灵衢总线,重构计算系统互联协议,实现超节点的统一内存编址和原生内存语义,大幅降低系统通信时延”
华为灵衢总线UB,构建超节点统一内存编址,纳秒级延迟,万卡集群通信时延降低60%
英伟达72卡、576卡,NVLink/C2C构建统一内存模型,GPU间直接访存,带宽130TB/s,突破通信墙。
AMDInfinityFabric实现CPU/GPU内存一致性,统一地址空间,系统通信延迟降低30%
国产海光、寒武、平头哥,大家已经熟知其优秀的超节点方案。
二、中国首创:全球半导体产业首次由中国企业提出新底层定律,话语权质变。
韬定律的核心逻辑,是以「时间缩微」系统性替代「几何缩微」,是对半导体演进逻辑的底层范式重构,规划在2031年将高端芯片的晶体管等效密度提升至与1.4nm制程工艺匹敌的水平。
不再追求晶体管的物理极致缩小,而是以压缩电路时间常数(τ,即信号传播时延)为核心目标,通过逻辑折叠等原创技术,构建贯穿器件、电路、芯片、系统的全栈协同优化体系,在成熟制程工艺下,实现晶体管等效密度与实际算力的革命性提升。
原理:只要能系统性降低时间常数,压缩信号在电路中的传播路径、减少传输损耗、缩短响应时延,就可以在不依赖先进制程工艺的前提下,大幅提升晶体管的等效集成密度,以及芯片的实际运算性能。这一逻辑,相当于在不扩大高速公路占地面积的前提下,通过优化路线设计、减少拥堵、缩短通行时长,直接提升单位时间的车辆通行效率。
不再需要突破EUV光刻设备的精度极限,不需要纠结原子级尺度的量子物理效应,也不需要承担先进制程带来的巨额量产成本。
通过全栈式的时延压缩,成熟制程工艺的芯片,可以实现匹敌甚至超越先进制程芯片的实际性能——这也是韬定律被行业视为“后摩尔时代新指导原则”的核心原因。韬定律并非单一的技术方案,而是一套覆盖从底层器件到上层系统的完整技术支撑体系,通过四层技术的协同优化,实现时间常数(τ)的系统性缩微。
更高算力密度:通过3D堆叠和Chiplet技术,在有限功耗与空间内集成更多计算单元,大幅提升AI核心算力。
降低访存延迟:将HBM与计算核心紧密集成,有效突破“内存墙”瓶颈,显著加速数据的处理与流转。
极致功耗优化:缩短信号传输路径,大幅降低能耗,实现同等功耗下的更高性能表现。
三、细分领域

参考资料:
20260512-招商证券-半导体:AI拉动从算力芯片扩散明显,自主可控产业链景气向好
本报告仅提供给九方金融研究所的特定客户及其他专业人士,用于市场研究、讨论和交流之目的。 未经九方金融研究所事先书面同意,不得更改或以任何方式传送、复印或派发本报告的材料、内容及其复印本予以任何第三方。如需引用、或经同意刊发,需注明出处为九方金融研究所,且不得对本报告进行有悖于原意的引用、删节和修改。 本报告由研究助理协助资料整理,由投资顾问撰写。本报告的信息均来源于市场公开消息和数据整理,本公司对报告内容(含公开信息)的准确性、完整性、及时性、有效性和适用性等不做任何陈述和保证。本公司已力求报告内容客观、公正,但报告中的观点、结论和建议仅反映撰写者在报告发出当日的设想、见解和分析方法应仅供参考。同时,本公司可发布其他与本报告所载资料不一致及结论有所不同的报告。本报告中的信息或意见不构成交易品种的买卖指令或买卖出价,投资者应自主进行投资决策,据此做出的任何投资决策与本公司或作者无关,自行承担风险,本公司和作者不因此承担任何法律责任。 投资顾问:王德慧(登记编号:A0740621120003) |
免责声明:以上内容仅供参考学习使用,不作为投资建议,此操作风险自担。投资有风险、入市需谨慎。
推荐阅读
相关股票
相关板块
相关资讯

扫码下载
九方智投app

扫码关注
九方智投公众号
头条热搜
涨幅排行榜
上海九方云智能科技有限公司 版权所有
证券投资咨询机构业务机构许可证:ZX0023
办公地址:上海市青浦区徐民东路88号1F(北塔、西北裙、东北裙、南裙)、2F(西北裙、南塔)、3F(北、西北裙、东北裙、南塔)、5F(南、北)、6F(南、北)、7F(南、北)、8F(南、北)、9F(南、北)、10F(南、北)、11F北、12F(南、北)
注册地址:上海市普陀区云岭东路89号12层1202室
 沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058
沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058
总经理信箱:xht_sh@newwinner.com.cn

















暂无评论
赶快抢个沙发吧